|
GeNN
2.2.3
GPU enhanced Neuronal Networks (GeNN)
|
|
GeNN
2.2.3
GPU enhanced Neuronal Networks (GeNN)
|
GeNN generates code according to the network model defined by the user, and allows users to include the generated code in their programs as they want. Here we provide a guideline to setup GeNN and use generated functions. We recommend users to also have a look at the Examples, and to follow the tutorials Tutorial 1 and Tutorial 2.
The user is first expected to create an object of class NNmodel by creating the function modelDefinition() which includes calls to following methods in correct order:
Then add neuron populations by:
for each neuron population. Add synapse populations by:
for each synapse population.
The modelDefinition() needs to end with calling NNmodel::finalize().
Other optional functions are explained in NNmodel class reference. At the end the function should look like this:
modelSpec.h should be included in the file where this function is defined.
This function will be called by generateALL.cc to create corresponding CPU and GPU simulation codes under the <YourModelName>_CODE directory.
These functions can then be used in a .cu file which runs the simulation. This file should include <YourModelName>_CODE/runner.cc. Generated code differ from one model to the other, but core functions are the same and they should be called in correct order. First, the following variables should be defined and initialized:
The following are declared by GeNN but should be initialized by the user:
modelDefinition)Core functions generated by GeNN to be included in the user code include:
allocateMem()deviceMemAllocate()initialize()initializeAllSparseArrays()convertProbabilityToRandomNumberThreshold()convertRateToRandomNumberThreshold()copyStateToDevice()push\<neuron or synapse name\>StatetoDevice()pull\<neuron or synapse name\>StatefromDevice()copyStateFromDevice()copySpikeNFromDevice()copySpikesFromDevice()stepTimeCPU()stepTimeGPU()freeMem()freeDeviceMem()Before calling the kernels, make sure you have copied the initial values of all the neuron and synapse variables in the GPU. You can use the push\<neuron or synapse name\>StatetoDevice() to copy from the host to the GPU. At the end of your simulation, if you want to access the variables you need to copy them back from the device using the pull\<neuron or synapse name\>StatefromDevice() function. Alternatively, you can directly use the CUDA memcopy functions. Copying elements between the GPU and the host memory is very costly in terms of performance and should only be done when needed.
Double precision floating point numbers are supported by devices with compute capability 1.3 or higher. If you have an older GPU, you need to use single precision floating point in your models and simulation.
GPUs are designed to work better with single precision while double precision is the standard for CPUs. This difference should be kept in mind while comparing performance.
While setting up the network for GeNN, double precision floating point numbers are used as this part is done on the CPU. For the simulation, GeNN lets users choose between single or double precision. Overall, new variables in the generated code are defined with the precision specified by NNmodel::setPrecision(unsigned int), providing GENN_FLOAT or GENN_DOUBLE as argument. GENN_FLOAT is the default value. The keyword scalar can be used in the user-defined model codes for a variable that could either be single or double precision. This keyword is detected at code generation and substituted with "float" or "double" according to the precision set by NNmodel::setPrecision(unsigned int).
There may be ambiguities in arithmetic operations using explicit numbers. Standard C compilers presume that any number defined as "X" is an integer and any number defined as "X.Y" is a double. Make sure to use the same precision in your operations in order to avoid performance loss.
User-defined model variables originate from core units such as neuronModel, weightUpdateModel or postSynModel objects. The name of a variable is defined when the model type is introduced, i.e. with a statement such as
This declares that whenever the defined model type of cardinal number myModel is used, there will be a variable of core name x. varType can be of scalar type (see Floating point precision). The full GeNN name of this variable is obtained by directly concatenating the core name with the name of the neuron population in which the model type has been used, i.e. after a definition
there will be a variable xEN of type double* available in the global namespace of the simulation program. GeNN will pre-allocate this C array to the correct size of elements corresponding to the size of the neuron population, n in the example above. GeNN will also free these variables when the provided function freeMem() is called. Users can otherwise manipulate these variable arrays as they wish. For convenience, GeNN provides functions pullXXStatefromDevice() and pushXXStatetoDevice() to copy the variables associated to a neuron population XX from the device into host memory and vice versa. E.g.
would copy the C array xEN from device memory into host memory (and any other variables that the neuron type of the population EN may have).
The user can also directly use CUDA memory copy commands independent of the provided convenience functions. The relevant device pointers for all variables that exist in host memory have the same name as the host variable but are prefixed with d_. For example, the copy command that would be contained in pullENStatefromDevice() will look like
where nEN is an integer containing the population size of the EN neuron population.
The same convention as for neuron variables applies for the variables of synapse populations, both for those originating from weightupdate models and from post-synaptic models, e.g. the variables in type NSYNAPSE contain the variable g of type float. Then, after
there will be a global variable of type float* with the name gENIN that is pre-allocated to the right size. There will also be a matching device pointer with the name d_gENIN.
gENIN needs to be interpreted differently for DENSE connectivity and sparse matrix based SPARSE connectivity representations. For DENSE connectivity gENIN would contain "n_pre" times "n_post" elements, ordered along the pre-synaptic neurons as the major dimension, i.e. the value of gENIN for the ith pre-synaptic neuron and the jth post-synaptic neuron would be gENIN[i*n_post+j]. The arrangement of values in the SPARSE representation is explained in section Connectivity types Since GeNN 2.0, there are no more explicitly hard-coded synapse and neuron variables. Users are free to name the variable of their models as they want. However, there are some reserved variables that are used for intermediary calculations and communication between different parts of the generated code. They can be used in the user defined code but no other variables should be defined with these names.
DT : Time step (typically in ms) for simulation; Neuron integration can be done in multiple sub-steps inside the neuron model for numerical stability (see Traub-Miles and Izhikevich neuron model variations in Neuron models).addtoinSyn : This variable is used by weightUpdateModel for updating synaptic input. The way it is modified is defined in weightUpdateModel.simCode or weightUpdateModel.simCodeEvnt, therefore if a user defines her own model she should update this variable to contain the input to the post-synaptic model.updatelinsyn : At the end of the synaptic update by addtoinSyn, final values are copied back to the d_inSyn<synapsePopulation> variables which will be used in the next step of the neuron update to provide the input to the postsynaptic neurons. This keyword designated where the changes to addtoinSyn have been completed and it is safe to update the summed synaptic input and write back to d_inSyn<synapsePopulation> in device memory.inSyn: This is an intermediary synapse variable which contains the summed input into a postsynaptic neuron (originating from the addtoinSyn variables of the incoming synapses) .Isyn : This is a local variable which contains the (summed) input current to a neuron. It is typically the sum of any explicit current input and all synaptic inputs. The way its value is calculated during the update of the postsynaptic neuron is defined by the code provided in the postSynModel. For example, the standard EXPDECAY postsynaptic model defines 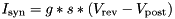 .
. addtoinSyn variables from all incoming synapses are automatically summed and added to the current value of inSyn.postSyntoCurrent code is assigned to Isyn and can then be used in neuron simCode like so: sT : As a neuron variable, this is the last spike time in a neuron and is automatically generated for pre and postsynaptic neuron groups of a synapse group i that follows a spike based learning rule (indicated by usesPostLearning[i]= TRUE for the ith synapse population).In addition to these variables, neuron variables can be referred to in the synapse models by calling $(<neuronVarName>_pre) for the presynaptic neuron population, and $(<neuronVarName>_post) for the postsynaptic population. For example, $(sT_pre), $(sT_post), $(V_pre), etc.
In Linux, users can call cuda-gdb to debug on the GPU. Example projects in the userproject directory come with a flag to enable debugging (DEBUG=1). genn-buildmodel.sh has a debug flag (-d) to generate debugging data. If you are executing a project with debugging on, the code will be compiled with -g -G flags. In CPU mode the executable will be run in gdb, and in GPU mode it will be run in cuda-gdb in tui mode.
On Mac, some versions of clang aren't supported by the CUDA toolkit. This is a recurring problem on Fedora as well, where CUDA doesn't keep up with GCC releases. You can either hack the CUDA header which checks compiler versions - cuda/include/host_config.h - or just use an older XCode version (6.4 works fine).
 1.8.11
1.8.11 
