GeNN generates code according to the network model defined by the user as described in User Manual , and allows users to include the generated code in their programs as they want . Here we provide a guideline to setup GeNN and use generated functions. We recommend users to also have a look at the Examples, and to follow the tutorials Tutorial 1 (C++) and Tutorial 2 (C++)follow the tutorials Tutorial 1 (Python) and Tutorial 2 (Python).
Simulating a network model
Any variables marked as uninitialised using the
uninitialisedVar() function or sparse connectivity not initialised using a snippet must be initialised by the user between calls to
initialize() and
initializeSparse().
Core functions generated by GeNN to be included in the user code include:
allocateMem()initialize()initializeSparse()stepTime()freeMem()getFreeDeviceMemBytes()
In order to correctly access neuron state and spikes for the current timestep, correctly accounting for delay buffering etc, you can use the getCurrent<var name><neuron name>(), get<neuron name>CurrentSpikes() and get<neuron name>CurrentSpikeCount() functions. Additionally, custom update groups (see Defining custom updates) can be simulated by calling update<group name>().
By setting GENN_PREFERENCES::automaticCopy the automaticCopy keyword to pygenn.GeNNModel.__init__ , GeNN can be used in a simple mode where CUDA automatically transfers data between the GPU and CPU when required (see https://devblogs.nvidia.com/unified-memory-cuda-beginners/). However, copying elements between the GPU and the host memory is costly in terms of performance and the automatic copying operates on a fairly coarse grain (pages are approximately 4 bytes). Therefore, in order to maximise performance, we recommend you do not use automatic copying and instead manually call the following functionsmethods when required:
push<neuron or synapse name>StateToDevice()pull<neuron or synapse name>StateFromDevice()push<neuron name>SpikesToDevice()pull<neuron name>SpikesFromDevice()push<neuron name>SpikesEventsToDevice()pull<neuron name>SpikesEventsFromDevice()push<neuron name>SpikeTimesToDevice()pull<neuron name>SpikeTimesFromDevice()push<neuron name>CurrentSpikesToDevice()pull<neuron name>CurrentSpikesFromDevice()push<neuron name>CurrentSpikeEventsToDevice()pull<neuron name>CurrentSpikeEventsFromDevice()pull<synapse name>ConnectivityFromDevice()push<synapse name>ConnectivityToDevice()pull<var name><neuron or synapse name>FromDevice()push<var name><neuron or synapse name>ToDevice()pushCurrent<var name><neuron name>ToDevice()pullCurrent<var name><neuron name>FromDevice()getCurrent<var name><neuron name>()copyStateToDevice()copyStateFromDevice()copyCurrentSpikesFromDevice()copyCurrentSpikesEventsFromDevice()
You can use
push<neuron or synapse name>StateToDevice() pygenn.genn_groups.Group.push_state_to_device to copy from the host to the GPU. At the end of your simulation, if you want to access the variables you need to copy them back from the device using the
pull<neuron or synapse name>StateFromDevice() function pygenn.genn_groups.Group.pull_state_from_device method or one of the more fine-grained functions listed above.
Extra Global Parameters
If extra global parameters have a "scalar" type such as float they can be set directly from simulation code. For example the extra global parameter "reward" of population "Pop" can be set withpygenn.NeuronGroup "pop" should first be initialised before pygenn.GeNNModel.load is called with:
pop.set_extra_global_param("reward", 5.0)
and subsequently can be updated with:
pop.extra_global_params["reward"].view[:] = 5.0
However, if extra global parameters have a pointer type such as
float*, GeNN generates additional functions to allocate, free and copy these extra global parameters between host and device:
allocate<egp name><neuron or synapse name>free<egp name><neuron or synapse name>push<egp name><neuron or synapse name>ToDevicepull<egp name><neuron or synapse name>FromDevice These operate in much the same manner as the functions for interacting with standard variables described above but the allocate, push and pull functions all take a "count" parameter specifying how many entries the extra global parameter array should be.
Extra global parameters with a pointer type such as
float* should be initialised and updated in the same manner but, if their value is changed after
pygenn.GeNNModel.load is called, the updated values need to be pushed to the GPU:
pop.extra_global_params["reward"].view[:] = [1,2,3,4]
pop.push_extra_global_param_to_device("reward", 4)
Extra global parameters can also be used to provide additional data to snippets used for variable (see
Variable initialisation) or sparse connectivity (see
Sparse connectivity initialisation) initialisation.
Like standard extra global parameters, GeNN generates additional functions to allocte, free and copy these extra global parameters between host and device:
allocate<egp name><var name><neuron or synapse name>free<egp name><var name><neuron or synapse name>push<egp name><var name><neuron or synapse name>ToDevicepull<egp name><var name><neuron or synapse name>FromDevice
These extra global parameters must be initialised before
pygenn.GeNNModel.load is called:
pop.vars["g"].set_extra_global_init_param("kernel", [1, 2, 3, 4])
Floating point precision
Double precision floating point numbers are supported by devices with compute capability 1.3 or higher. If you have an older GPU, you need to use single precision floating point in your models and simulation. Furthermore, GPUs are designed to work better with single precision while double precision is the standard for CPUs. This difference should be kept in mind while comparing performance.
Typically, variables in GeNN models are defined using the scalar type. This type is substituted with "float" or "double" during code generation, according to the model precision. This is specified with ModelSpec::setPrecision() – either GENN_FLOAT or GENN_DOUBLE. GENN_FLOAT is the default valuewith the first parameter to pygenn.GeNNModel.__init__ as a string e.g. "float".
There may be ambiguities in arithmetic operations using explicit numbers. Standard C compilers presume that any number defined as "X" is an integer and any number defined as "X.Y" is a double. Make sure to use the same precision in your operations in order to avoid performance loss.
Working with variables in GeNN
Model variables
User-defined model variables originate from classes derived off the NeuronModels::Base, WeightUpdateModels::Base or PostsynapticModels::Base classes. The name of model variable is defined in the model type, i.e. with a statement such as
var_name_types=[("V", "scalar")]
When a neuron or synapse population using this model is added to the model, the full GeNN name of the variable will be obtained by concatenating the variable name with the name of the population. For example if we add a population called Pop using a model which contains our V variable, a variable VPop of type scalar* will be available in the global namespace of the simulation program. GeNN will pre-allocate this C array to the correct size of elements corresponding to the size of the neuron population. Users can otherwise manipulate these variable arrays as they wish.
When a neuron or synapse population using this model is added to the model, it is built (with
pygenn.GeNNModel.build) and loaded (with
pygenn.GeNNModel.load), it is available to Python code via a numpy memory view into the host memory:
pop.vars["V"].view[:] = 1.2
For convenience, GeNN provides functions to copy each state variable from the device into host memory and vice versa e.g.
pullVPopFromDevice() and pushVPoptoDevice() pygenn.genn_groups.Group.pull_var_from_device and pygenn.genn_groups.Group.push_var_to_device. Alternatively, all state variables associated with a population can be copied using a single call E.g.
pullPopStateFromDevice();
pop.pull_state_from_device()
These conventions also apply to the the variables of postsynaptic and weight update models.
- Note
- Be aware that the above naming conventions do assume that variables from the weightupdate models and the postSynModels that are used together in a synapse population are unique. If both the weightupdate model and the postSynModel have a variable of the same name, the behaviour is undefined.
Built-in Variables in GeNN
GeNN has no explicitly hard-coded synapse and neuron variables. Users are free to name the variable of their models as they want. However, there are some reserved variables that are used for intermediary calculations and communication between different parts of the generated code. They can be used in the user defined code but no other variables should be defined with these names.
DT : Time step (typically in ms) for simulation; Neuron integration can be done in multiple sub-steps inside the neuron model for numerical stability (see Traub-Miles and Izhikevich neuron model variations in Neuron models).
- Note
- DT exceptionally does not require bracketing with $(.)
t : The current time as a floating point value, typically interpreted as in units of msid : The index of a neuron in a neuron population; can be used in the context of neurons, current sources, postsynaptic models, and pre- and postsynaptic weight update modelsid_syn : index of a synapse in a synapse populationid_pre : Used in a synapse context. The index of the pre-synaptic neuron in its population.id_post : Used in a synapse context. The index of the post-synaptic neuron in its population.inSyn : Used in the context of post_synaptic models. This is an intermediary synapse variable which contains the summed input into a postsynaptic neuron (originating from the $(addToInSyn, X) or $(addToInSynDelay, X, Y) functions of the weight update model used by incoming synapses).Isyn : This is a local variable which contains the (summed) input current to a neuron. It is typically the sum of any explicit current input and all synaptic inputs. The way its value is calculated during the update of the postsynaptic neuron is defined by the code provided in the postsynaptic model. For example, the standard PostsynapticModels::ExpCond postsynaptic model defines apply_input_code="$(Isyn) += $(inSyn)*($(E)-$(V));"
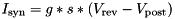 . The value of $(Isyn) resulting from the apply input code can then be used in neuron sim code like so:
. The value of $(Isyn) resulting from the apply input code can then be used in neuron sim code like so: $(V)+= (-$(V)+$(Isyn))*DT
sT : This is a neuron variable containing the spike time of each neuron and is automatically generated for pre and postsynaptic neuron groups if they are connected using a synapse population with a weight update model that has SET_NEEDS_PRE_SPIKE_TIME(true) or SET_NEEDS_POST_SPIKE_TIME(true)is_pre_spike_time_required=True or is_post_spike_time_required=True set.prev_sT: This is a neuron variable containing the previous spike time of each neuron and is automatically generated for pre and postsynaptic neuron groups if they are connected using a synapse population with a weight update model that has SET_NEEDS_PREV_PRE_SPIKE_TIME(true) or SET_NEEDS_PREV_POST_SPIKE_TIME(true)is_prev_pre_spike_time_required=True or is_prev_post_spike_time_required=True set.
In addition to these variables, neuron variables can be referred to in the synapse models by calling $(<neuronVarName>_pre) for the presynaptic neuron population, and $(<neuronVarName>_post) for the postsynaptic population. For example, $(sT_pre), $(sT_post), $(V_pre), etc.
Spike Recording
Especially in models simulated with small timesteps, very few spikes may be emitted every timestep, making calling pull<neuron name>CurrentSpikesFromDevice() or pull<neuron name>SpikesFromDevice() pygenn.NeuronGroup.pull_current_spikes_from_device every timestep very inefficient. Instead, the spike recording system allows spikes and spike-like events emitted over a number of timesteps to be collected in GPU memory before transferring to the host. Spike recording can be enabled on chosen neuron groups with the NeuronGroup::setSpikeRecordingEnabled and NeuronGroup::setSpikeEventRecordingEnabled methods pygenn.NeuronGroup.spike_recording_enabled and pygenn.NeuronGroup.spike_event_recording_enabled properties. Remaining GPU memory can then be allocated at runtime for spike recording by calling allocateRecordingBuffers(<number of timesteps>) from user codeusing the num_recording_timesteps keyword argument to pygenn.GeNNModel.load. The data structures can then be copied from the GPU to the host using the pullRecordingBuffersFromDevice() function pygenn.GeNNModel.pull_recording_buffers_from_device method and the spikes emitted by a population can be accessed in bitmask form via the recordSpk<neuron name> variablevia the pygenn.NeuronGroup.spike_recording_data property Similarly, spike-like events emitted by a population can be accessed via the recordSpkEvent<neuron name> variable pygenn.NeuronGroup.spike_event_recording_data property. To make decoding the bitmask data structure easier, the writeBinarySpikeRecording and writeTextSpikeRecording helper functions can be used by including spikeRecorder.h in the user code.
Debugging suggestions
In Linux, users can call
cuda-gdb to debug on the GPU. Example projects in the
userproject directory come with a flag to enable debugging (–debug). genn-buildmodel.sh has a debug flag (-d) to generate debugging data. If you are executing a project with debugging on, the code will be compiled with -g -G flags. In CPU mode the executable will be run in gdb, and in GPU mode it will be run in cuda-gdb in tui mode.
- Note
- Do not forget to switch debugging flags -g and -G off after debugging is complete as they may negatively affect performance.
On Mac, some versions of clang aren't supported by the CUDA toolkit. This is a recurring problem on Fedora as well, where CUDA doesn't keep up with GCC releases. You can either hack the CUDA header which checks compiler versions - cuda/include/host_config.h - or just use an older XCode version (6.4 works fine).
On Windows models can also be debugged and developed by opening the sln file used to build the model in Visual Studio. From here files can be added to the project, build settings can be adjusted and the full suite of Visual Studio debugging and profiling tools can be used.
- Note
- When opening the models in the
userproject directory in Visual Studio, right-click on the project in the solution explorer, select 'Properties'. Then, making sure the desired configuration is selected, navigate to 'Debugging' under 'Configuration Properties', set the 'Working Directory' to '..' and the 'Command Arguments' to match those passed to genn-buildmodel e.g. 'outdir' to use an output directory called outdir.
To build a debug version of PyGeNN, you first need to build debug dynamic libraries. On Linux, these can be built directly into the PyGeNN directory:
make DEBUG=1 DYNAMIC=1 LIBRARY_DIRECTORY=`pwd`/
pygenn/genn_wrapper/
On Windows, building these requires two steps:
msbuild genn.sln /t:Build /p:Configuration=Debug_DLL
copy /Y lib\genn*Debug_DLL.* pygenn\genn_wrapper
Finally the debug Python extension can be built with setup tools using:
python setup.py build_ext --debug develop
Previous |
Top |
Next
 1.8.13
1.8.13