Software Developer Blog: Running away
JamieAfter spending a long time updating GeNN's code generator to generate more efficient CUDA kernels which have the side benefit of compiling much more quickly, there remained something of a dirty secret.
The runner.cc file which contains the helper functions generated by GeNN for allocating memory and copying variables between GPU and CPU could still easily grow to the point that compilation would take an extremely long time and consume all available memory.
For our multi-area model implementation, I added various options which turn off the generation of empty functions and, as everything in this model was generated on the GPU anyway, I also turned off the generation of host copies of almost all variables.
This resulted in a paltry 40 mbyte runner.cc which compiled in a couple of minutes which, for a model this size, is just about acceptable.
However, as users have started making bigger models and not always wanting to generate everything on the GPU, this issue has kept reappearing.
Jinjaly investigating
To investigate this in a slightly simpler way than just building larger and larger GeNN models until things break, I used Jinja to build a template that could generate fake runner.cc files containing varying number of arrays, representing the state variables in a real model.
The heart of this template looked something like this:
// Push and pull functions {% for array in arrays %} void push{{array.name}}ToDevice() { CHECK_CUDA_ERRORS(cudaMemcpy(d_{{array.name}}, {{array.name}}, {{array.size}} * sizeof(float), cudaMemcpyHostToDevice)); } void pull{{array.name}}FromDevice() { CHECK_CUDA_ERRORS(cudaMemcpy({{array.name}}, d_{{array.name}}, {{array.size}} * sizeof(float), cudaMemcpyDeviceToHost)); } {% endfor %} void allocateMem() { CHECK_CUDA_ERRORS(cudaSetDevice(0)); {% for array in arrays %} CHECK_CUDA_ERRORS(cudaHostAlloc(&{{array.name}}, {{array.size}} * sizeof(float), cudaHostAllocPortable)); CHECK_CUDA_ERRORS(cudaMalloc(&d_{{array.name}}, {{array.size}} * sizeof(float))); {% endfor %} }
this template (saved in runner.cc.template) could then be used to generate C++ and print it to stdout like:
from jinja2 import Template with open("runner.cc.template", "r") as file: template = Template(file.read()) arrays = [{"name": f"array_{i}", "size": 1000} for i in range(num_arrays)] print(template.render(arrays=arrays))
On Linux, the C++ could then be built using the same command line used by GeNN itself (some options omitted for brevity) and timed using the /usr/bin/time (I recently discovered that command time can be used as an alternative way of disambiguating this from the bash builtin time):
/usr/bin/time -v nvcc -c -x cu -arch sm_86 -std=c++11 test.cc
Initial experiments showed that while both the wall clock time and maximum resident set size (roughly analagous to peak physical memory usage) grow approximately linearly (much to my relief after reading way too many horror stories on Bruce Dawson's excellent blog) with the number of arrays, it still grew extremely rapidly:
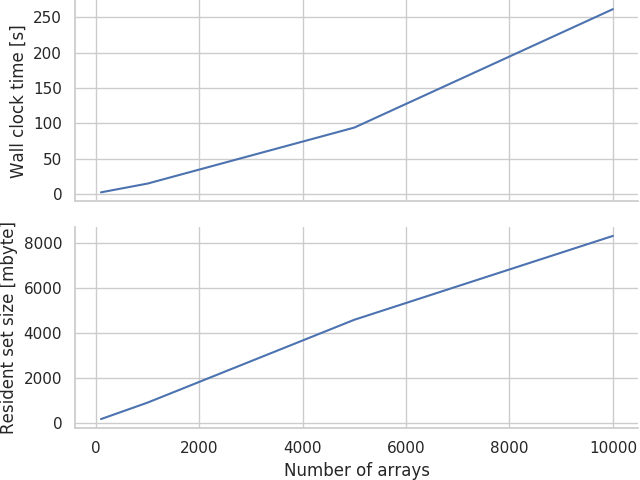
Therefore, a model with 10000 arrays will take over 4 minutes and around 8 gbyte of memory to compile — neither of which are really acceptable. To put this in perspective, if you split a model up into about 100 populations and connect most of the permutations together (this is an all-too-reasonable assumption in many areas of the mammalian brain), you could easily reach this many variables.
So....what is NVCC doing with all this time and memory?
runner.cc only contains host code (NVCC is just used to ensure the same compiler/options across execution units and to deal with setting up the CUDA linker/include paths) but, when you pass a 5 mbyte runner.cc file to NVCC, the file that is passed on to the host compiler (GCC) has grown to 15 mbyte!
However, this turned out to be simply because NVCC is in charge of running the preprocessor so that 10 mbyte is 'just' the result of expanding macros and including C++ standard library header files!
Profiling
Around this point, I remembered reading a blog post about profiling compiler times on yet another excellent blog and turned on the -ftime-report GCC option.
As the blog promised, this generates a gargantuan report which starts by splitting the compilation time of this 10000 array model into 'phases':
phase setup : ... 0.00 ( 0%) wall 1384 kB ( 0%) phase parsing : ... 20.81 ( 9%) wall 1794944 kB (25%) phase lang. deferred : ... 0.02 ( 0%) wall 2426 kB ( 0%) phase opt and generate : ... 214.14 (91%) wall 5412439 kB (75%) phase finalize : ... 0.54 ( 0%) wall 0 kB ( 0%)
Somewhat surprisingly (as, after all, we're throwing a massive source file at GCC), the vast majority of time is spent in "opt and generate" (code-generation and optimisation) rather than in parsing. Looking a little further down, where the report contains a seeminly unsorted list of processes within phases, the only other 'hot' line is:
expand vars : ... 101.93 (43%) wall 50597 kB ( 1%)
but, as a non-GCC developer, this doesn't help me a great deal....back to pursuing random hunches!
Smoking gun
As there's no virtual functions in this code, my C++ prejudices suggest that only exceptions could possibly be to blame and, as each of those CHECK_CUDA_ERRORS macros hides a throw std::runtime_error, maybe that's not unreasonable.
Generating all that zero-cost abstraction must involve expanding a lot of variables....right!?
How about if we replace our current implemementation of CHECK_CUDA_ERRORS:
#define CHECK_CUDA_ERRORS(call) {\ cudaError_t error = call;\ if(error != cudaSuccess) {\ throw std::runtime_error(__FILE__": " \ + std::to_string(__LINE__) \ + ": cuda error " \ + std::to_string(error) \ + ": " + cudaGetErrorString(error));\ }\ }
with:
#define CHECK_CUDA_ERRORS(call) {\ cudaError_t error = call;\ assert(error == cudaSuccess); \ }
or even:
#define CHECK_CUDA_ERRORS(call) {\ cudaError_t error = call;\ if(error != cudaSuccess) {\ std::abort();\ }\ }
Some template-meddling and sweeping later we can produce:
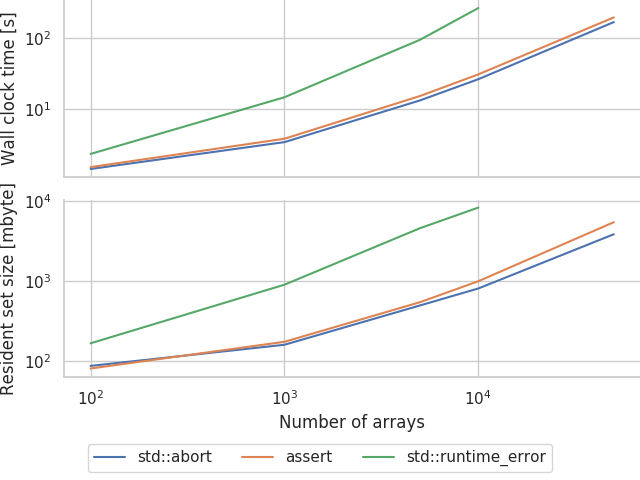
Seems like this actually works! Our 10000 array model now only takes 30 seconds and less than 1 gbyte of memory to compile which is much more reasonable!
However, are the exceptions really to blame?
Compile times seem much better when using the single-threaded CPU backend and that allocates memory with new[] (obviously, modern C++ rules don't apply in generated code...) which throws std::bad_alloc to signal failure.
Admittedly, because there's no need to copy data when everthing's on the CPU, this backend generates empty 'push' and 'pull' functions so there's less code to compile overall but, if generating exception handling code was the problem, you would expect issues here too.
Maybe expanding all that message-generating code is the real issue...
How about we hack the following additional variants into the template:
#define CHECK_CUDA_ERRORS(call) {\ cudaError_t error = call;\ if(error != cudaSuccess) {\ throw std::runtime_error();\ }\ }
and
#define CHECK_CUDA_ERRORS(call) {\ cudaError_t error = call;\ if(error != cudaSuccess) {\ std::cerr << __FILE__ << ": " << __LINE__;\ std::cerr << ": cuda error " << error << ": ";\ std::cerr << cudaGetErrorString(error) << std::endl;\ std::abort();\ }\ }
and sweep:
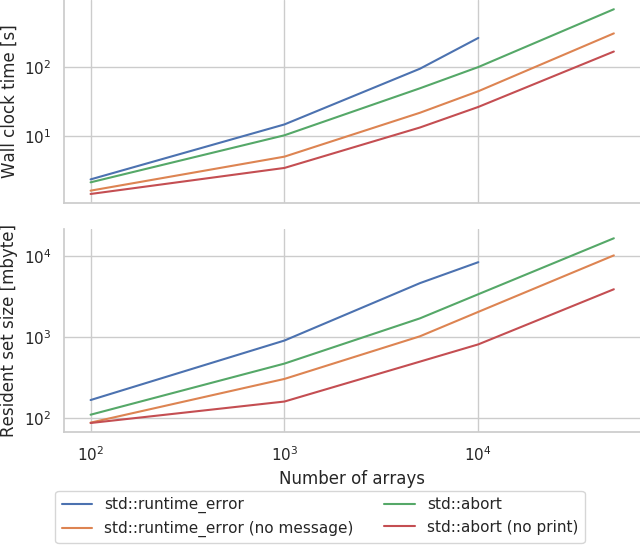
std::abort is definitely easier on the compiler than throwing exceptions but, compiling the message generation code also seems to make a large difference.
MSVC
The other compiler I often use with GeNN is Microsoft Visual C++.
I can't quite face repeating this whole process again but, initial tests suggest that this optimisation is even more valuable here.
Using the simplest std::abort raising CHECK_CUDA_ERRORS macro, the 10000 array model can be compiled in around 19 seconds whereas, using the original exception-throwing macro...I have given up waiting after around 1 hour!
Implementing a workaround
GeNN is approaching the end of the 4.X release cycle so, for now, I have added a simple but slightly hacky workaround for these issues by adding a generateSimpleErrorHandling flag to GeNN's CUDA backend to switch from generating code with the previous full-fat CHECK_CUDA_ERRORS macro to the simplest version which simply calls std::abort without generating a message. This can be turned on from C++ like:
void modelDefinition(NNmodel &model) { ... GENN_PREFERENCES.generateSimpleErrorHandling = true; ... }
or from Python like:
model = GeNNModel("float", "my_model", generateSimpleErrorHandling=True)
Real models
The largest model we currently have to play with with is the multi-area cortical model.
Although it has 64516 synapse groups, due to its use of procedural connectivity (where all synaptic connectivity, weights and delays are generated on the fly), it doesn't actually have any per-synapse group variables with push and pull functions.
Nonetheless, using the new simple error handling reduces the compilation time of the runner.cc from 155 to 129 seconds.
Finally, although it is not possible to run the model in this way as no single GPU has enough memory, we can generate a runner.cc from this model with standard, in-memory sparse connectivity and push and pull functions for each variable.
This results in a nightmarish, 114 mbyte runner.cc which, using the original CHECK_CUDA_ERRORS macro, would definitely be impossible to compile on any reasonable machine.
However, using the new simplified macro, the runner can be compiled in just over 20 minutes and requires just over 14 gbyte of memory — still pretty unusable but definitely progress!
Long-term solutions
The majority of the time, the errors which the CHECK_CUDA_ERRORS macro is aiming to catch are out of memory errors in the allocateMem function and errors that occured during (asynchronous) kernel launches that are only caught at the next push or pull call (which are typically the main synchronisation points) so perhaps, in future, we could adopt a more targetted error-handling approach which provides a balance between sufficient debugging information and compilation time.
However, while the error handling changes discussed here allow the current approach to generating runner.cc files to scale a bit further, the code we are generating is still pretty pathological, least of all because the Windows PE executable format has a limit of 65535 symbol limit which you can hit quite easily with a large model.
Early this year, I made an attempt at re-writing the code generator to apply the same merging strategy GeNN uses elsewhere to runner.cc.
This means that all the variables associated with neuron and synapse populations with the same types of state variable can be allocated using one piece of shared generated code.
While this works, it adds yet more complexity to GeNN and fundamentally breaks the 'classic' way of using GeNN from C++, where you link some C++ simulation code against your generated code and can access state variables directly by name.
However, based on this investigation, maybe that project needs resurrecting!
All the code I've developed to explore this problem is available from my Github.